
[论文学习]SCoRe:通过强化学习让LLM学会自我纠正
资料
论文:[2409.12917] Training Language Models to Self-Correct via Reinforcement Learning
简介
本文提出了一种名为 SCoRe 的多轮在线强化学习方法,以提升大型语言模型(LLMs)的自我纠正能力,避免依赖额外的监督或更强的模型。研究表明,传统的监督微调(SFT)方法在训练自我纠正时常遇到分布不匹配或行为坍缩的问题,使得模型无法有效改正自身错误。SCoRe 通过在模型自身生成的错误更正轨迹上进行训练,并结合适当的正则化,成功避免这些问题。该方法在 MATH 和 HumanEval 任务上显著提升了 Gemini 1.0 Pro 和 1.5 Flash 模型的自我纠正性能,分别提高了 15.6% 和 9.1%。论文还通过实验分析了传统 SFT 失败的原因,并证明强化学习在训练自我纠正能力方面的必要性。
之前的工作,要么通过prompt工程,要么训练一个专门的纠错模型,要么在纠错数据上SFT,这些方法的缺陷的效果不好,以及限制较多,这篇文章提出了SCoRe,来让模型自主学会纠错行为。
多轮纠错的设定比较简单(如图),第一轮让模型先给个回复,然后第二轮给一个自我纠错的指令,让模型有错就改,没错就还按之前的答案输出。不过这个任务的设置本身就非常难。就像让你解一道数学题,然后不给任何提示立马让你再解一遍,如果第一遍错了,第二遍要改过来确保解法正确。关键是,这中间还不允许你仔细检查下上一次解法是不是哪里有错误(比如写一些CoT逐步骤的检查下),而是直接让你给出第二轮的标准正确解法。这个设定与人类的正常纠错过程非常不一样,人在纠错时,往往会采用check关键步骤是不是正确,换一种解题方法,或者把结果代回到题目中验证,总之肯定不会傻傻的再做一遍。不教给模型任何纠错的方法或过程,而是直接就让模型纠,SFT要是能学会才怪了。

自生成数据的SFT不足以进行自校正
作者首先实验了直接在纠错数据上SFT的效果,采用了两种方法。STar和Pair-SFT,前者主要思路是通过prompt产生大量纠错数据,只保留成功纠错的数据来进行SFT;后者是[2211.00053] Generating Sequences by Learning to Self-Correct这篇文章的变体,直接把错误数据和正确数据拼接在一起,构造纠错数据。
评估标准
作者为纠错这个设置定义了一些metric:
(1) Accuracy@t1:模型第一次尝试的准确率;
(2) Accuracy@t2:第二次尝试时模型的准确度;
(3) Δ(t1, t2):模型准确度的净改进,第一次和第二次尝试之间的差异,衡量自我纠正的功效,
(4) Δi→c(t1,t2):第一次尝试时不正确但第二次尝试时正确的问题比例,它衡量自我纠正可以解决多少新问题;
(5) Δc→i(t1, t2): 的分数在第一次尝试中正确但在第二次尝试中变得不正确的问题,其测量模型对如何使响应正确的理解程度。
所以,优化方向是保持Acc@t1尽可能不变或提升,然后拉大Δ(t1,t2),并且拉大的方式应该是Δi→c(t1,t2)尽可能多提升,Δc→i(t1,t2)要尽可能小,防止把第一轮正确的反而改错了。
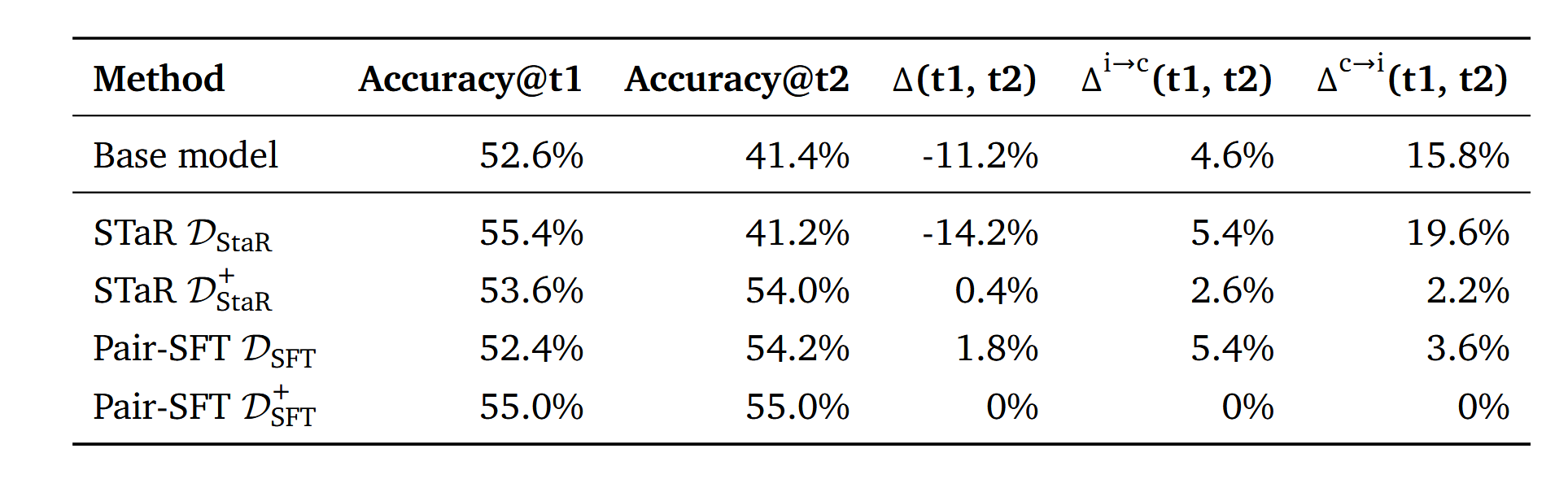
前期结果验证
可以看到,Base Model效果并不好,于是认为,模型没有专门SFT训练过这类任务,效果不好也很正常,于是用两种方法构建了多轮纠错数据:
- STaR:基于STaR构建由错到对的轨迹,构成数据集
- Pair-SFT:随机组合错误和正确的回复,构成数据集
同时作者觉着 DSTaR 训出来的效果不好,是模型不知道什么时候应该纠错(DSFT 效果还行可能是因为y~i+的随机采样带来的结果多样性)。也许是训练集都是InCorrect→Correct的数据,缺少Correct→Correct的数据导致的。于是,在训练集中加入了一些Correct→Correct的数据,形成了DSTaR+ 和DSFT+。
这两个数据训完,发现虽然Δc→i(t1,t2)没问题了,但模型倾向于完全不做任何纠错的修改。Δ(t1,t2)基本上也没了。看起来InCorrect→Correct和Correct→Correct的数据分布很重要,但不管是什么样的数据分布,模型通过SFT都很难正确理解什么是自我纠正。
既然模型不进行自我纠正了,那是因为模型倾向于原封不动的Copy第一轮的结果,还是做了修改了但给出同样的答案呢?用两次回复的编辑距离可以得到结果。
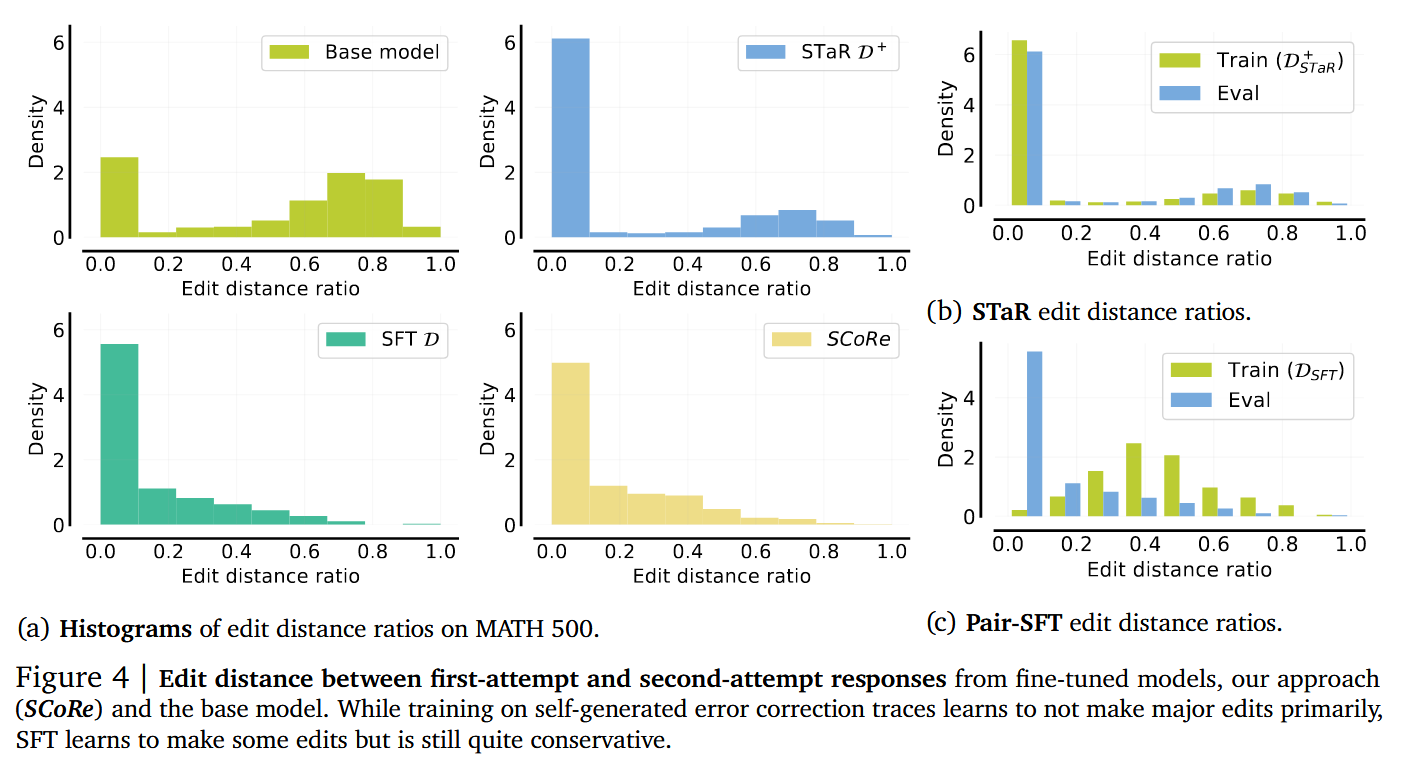
可以看到Base Model的两次回复的编辑距离很大,但是DSTaR+ 和DSFT训出来的Model,模型会更保守,倾向于不怎么做修改)。而分析训练和验证回复的编辑距离分布,发现模型能够更好的拟合STaR方法构建的训练数据分布,而不太能拟合Pair-SFT方式构建出的训练集分布。
因此,作者在Pair-SFT上继续分析了在固定的第一轮回复上,以及在模型自生成的第一轮回复上,随着训练进展模型的纠错准确率变化。前者可以一定程度认为是在Off-Policy回复上的纠错,后者认为是On-Policy的。
前期验证结论
基于这些观察,作者给出结论:SFT不足以让模型学会自我纠正的能力。
- STaR这种单一模式的数据,会让模型倾向于做很微小的修改。
- Pair-SFT形式的数据,由于分布漂移等问题,会导致自我纠错能力的退化。
因此新的方法需要满足:
- [1] 使用自生成的轨迹(On-Policy)来减轻分布不匹配带来的影响。
- [2] 要在学习中,避免模型只做微小的修改,导致collapse现象。

解决方案就是设计online-RL方法,更谨慎地初始化模型和设计Reward。SFT通常不适合学习非常细微的模型行为,也容易引起一些不太合理的行为(感觉主要是由于分布漂移或容易走一些捷径导致没有学习正确的策略)。
作者把之前模型不能学会自我纠错归结于两点:
(1)分布偏移,训练后的模型能够纠正生成数据的基本模型所犯的错误,但这些收益不会转移到自我纠正在学习模型自身的错误下;
(2)行为崩溃,模型简单学会产生最好的第一次尝试响应,然后进行肤浅的修改或不进行任何修改。
为了解决这两个问题,SCoRe采用了两阶段的强化学习微调。
SCoRe:通过多轮强化学习进行自我校正
首先,online-RL方法能解决上述[1]的问题,但对于[2]是否能解决并不确定,所以作者先尝试一下,用naive multi-turn RL,是否能够解决[2]的问题。结果发现,使用naive multi-turn RL(Figure 5-绿色线),随着训练进展,虽然第一轮尝试、第二轮修正效果都在提升,但是第二轮的修正与第一轮尝试的效果趋势基本上一致,这说明模型会倾向于基本上不做修改,policy在RL过程中迅速的学会了不去做修改,导致没有学会自我纠正的能力。
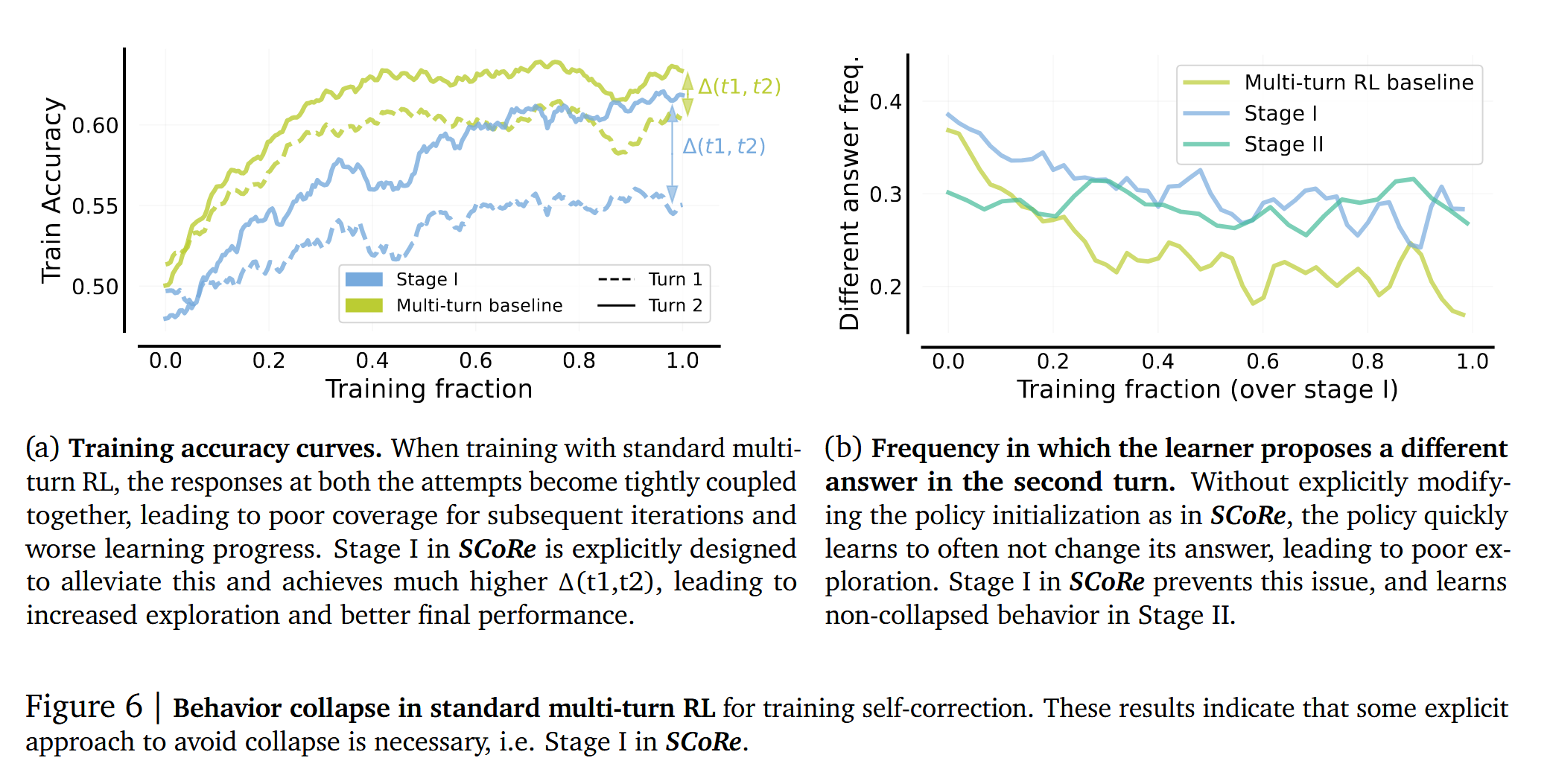
为什么会发生这样的事情?作者猜测,模型有两种学习的策略:(1) 学习第二次尝试要改进第一次尝试的结果(也就是自我纠正);(2) 将第一次尝试做的足够好,第二次就不做修改。很显然,只有前者是在学习自我纠正的能力。但对于过参数化的语言模型来说,这两种策略都是可以选择的,并不存在孰优孰劣的问题。这里遇到的问题就和一开始提到的meta-learning中的问题比较相近,模型究竟是学习某一道具体题目的解法,还是学习其背后隐藏的用于解决问题的元方法?我感觉,可能和大多数人类一样,如果不去特定地约束和训练,大多人只是机械的记忆某个具体的特例,而不是总结背后的规律和方法,因为记忆特例看起来总是比总结规律要容易很多。
因此,作者设计了SCoRe的方法,将模型的训练拆分为两个阶段:
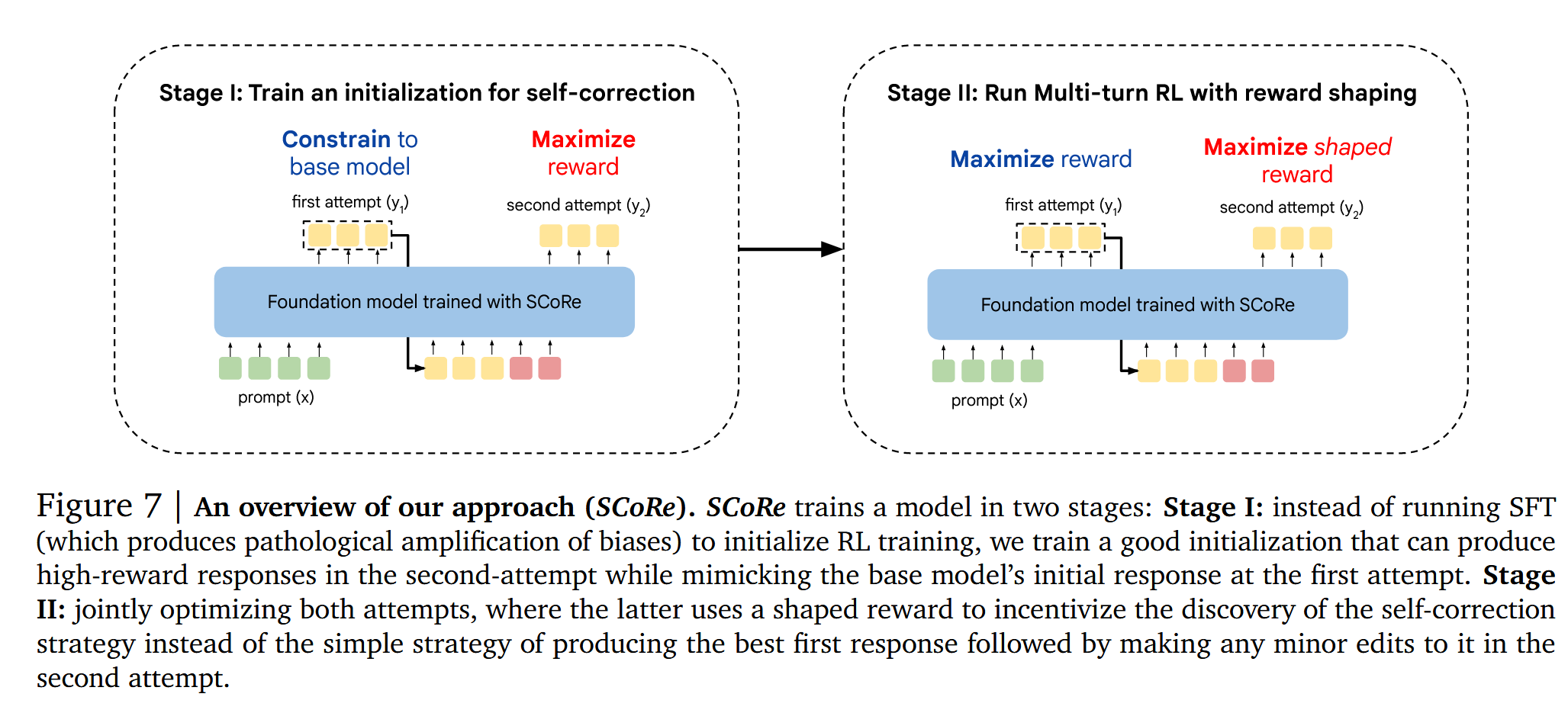
阶段一(Stage I):让模型学习如何在第二次尝试的时候将第一轮的错误纠正过来,同时维持第一轮的回复分布基本不变(不让模型学习第一轮就把题目做对,进而导致分布漂移,使模型没有去学习正确的纠错行为)。具体方法是,给第一轮回复加一个KL约束。

阶段二(Stage II):在Stage I的基础上,运行之前的multi-turn RL,通过Reward Shaping给自我纠正得到正确结果的行为更大的奖励。

具体来说,通过Reward Shaping来激励模型更好的学习自我纠正,将第二轮的奖励项追加一个additional bonus。这个bonus仅强调两轮的结果正确性出现反转的情况,如果第一轮错第二轮对,将给一个很高bonus;如果第一轮对第二轮错,将给一个很大的penalty;如果两次结果正确性一样,则不会添加这个bonus,防止模型不去做明显的修改。

最后,作者将两个阶段组合并交替训练。通过这样的online-RL设计,模型可以学习更微妙的策略,从而避免的非预期地学习错误的行为模式,同时有效的避免了分布漂移问题。
实际上,我们再想一想背后的原理,这种设计和人类学习的过程也比较接近。先自己刷题,找人教你改错并纠正,这些错误必须你自己犯的,看别人犯的错误,学习效率可能就没那么高。然后总结自我纠正的方法,一方面要提升刷题的正确率,另一方面激励自己去纠正自己犯的错误,纠对了就奖励个甜枣,纠错了就打一巴掌。等刷一段时间了,自己犯的错误又不会就纠正了,就在再找人教一下。
实验
实验设置
论文的实验主要围绕以下几个关键问题展开:
- SCoRe 在 MATH 和代码生成任务中的表现如何?
- SCoRe 是否能与推理时的计算扩展方法(如自一致性采样)结合?
- SCoRe 的关键组件(如两阶段训练、奖励塑形等)对最终性能的影响?
实验数据集
- MATH(数学推理):
- 数据集:MATH(Hendrycks et al., 2021)
- 训练/测试划分:4500 个训练样本,500 个测试样本(MATH500)
- 评价标准:模型回答的准确性(Accuracy@t1、Accuracy@t2)、自我纠正增益 Δ(t1, t2)
- 代码生成:
- 数据集:MBPP、HumanEval
- 训练/测试划分:在 MBPP 上训练、在 HumanEval 进行测试
- 评价标准:代码生成任务中,模型回答是否通过所有测试用例、MBPP-R:用于测试模型对错误代码修复能力的离线任务
实验结果
Math上看,虽然最终Δ(t1,t2)仍然不高,只有+4.4pp,但Δc→i(t1,t2)显著降低了,而且Acc@t1非常明显的提升了+7pp。如果对比其他的方法,事实上纠错能力是有非常大的改善的,并没有因为第一次尝试效果提升了,而影响了第二轮的自我纠正。
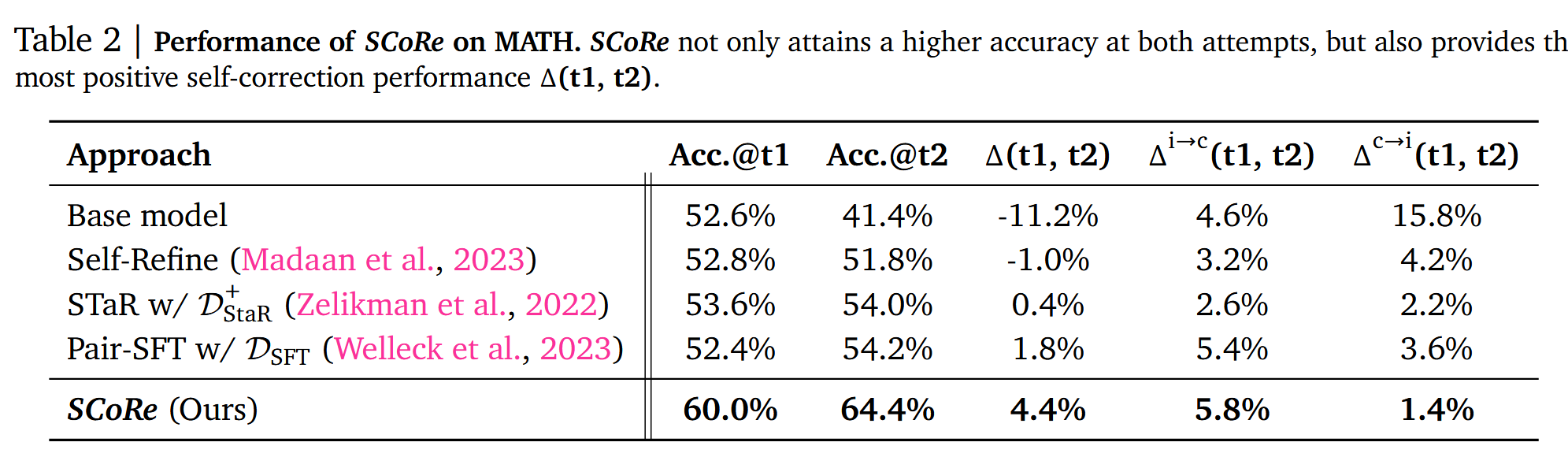
在代码方面,尽管只使用了MBPP数据训练,在HumanEval上测试,可以看到自我纠错的能力得到了良好的泛化,Δ(t1,t2)达到了+12.2pp。
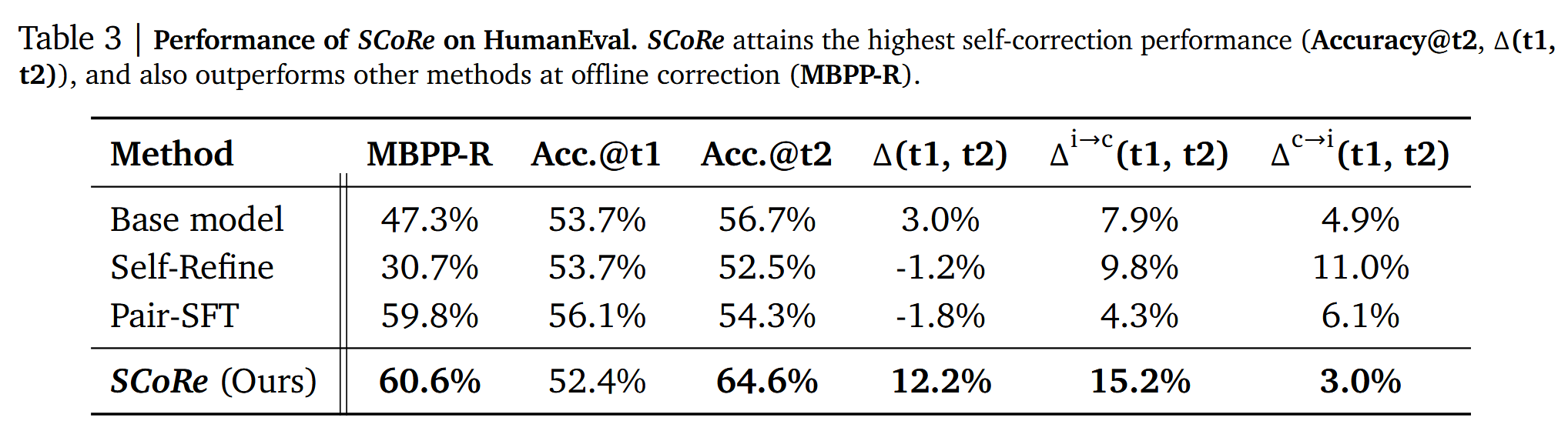
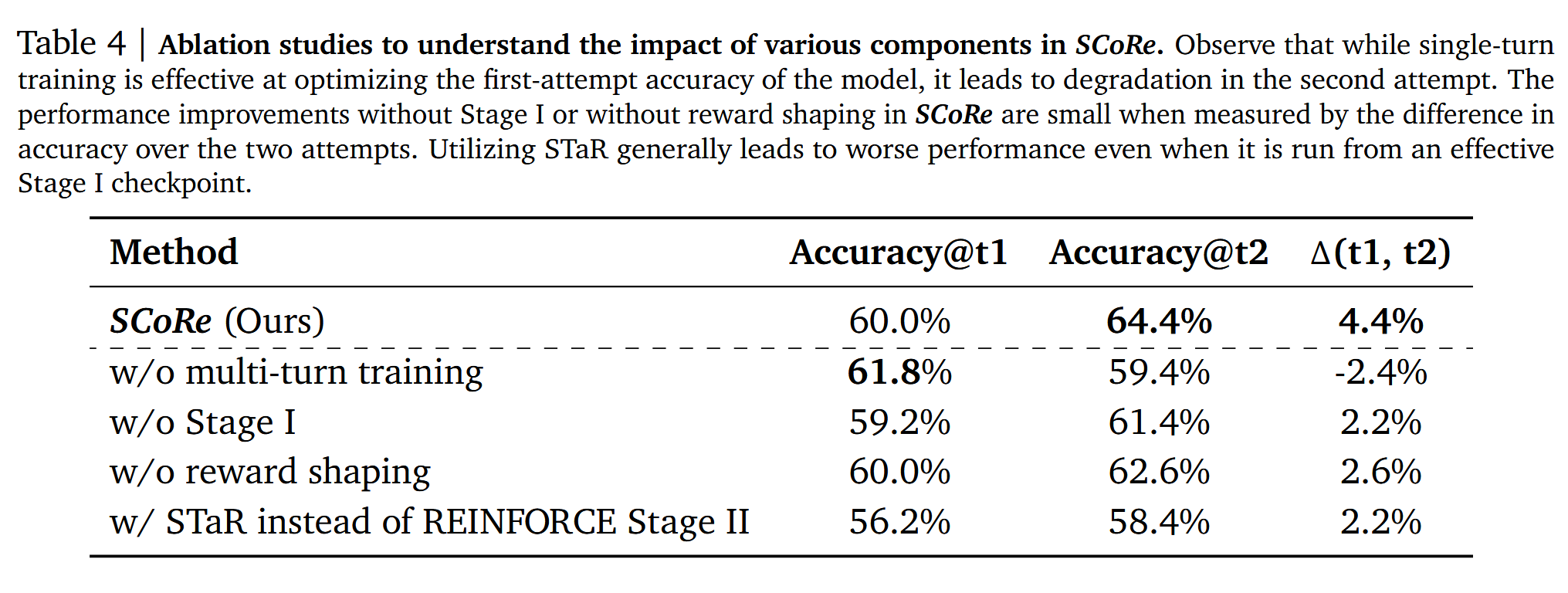
消融实验方面,单轮训练可以有效提升首轮尝试效果,但是会导致多轮自我纠正能力退化。缺少Stage I或Reward Shaping会导致自我纠正能力不足。用STaR替换Stage II会导致整体效果的退化。
总结
本文提出了一种名为 SCoRe 的多轮强化学习方法,旨在提升LLMs的自我纠正能力,而无需额外的监督或更强的模型支持。传统的监督微调方法在自我纠正任务上常遇到分布偏移和行为坍缩的问题,导致模型难以有效改正自身错误。SCoRe 通过两阶段训练策略:第一阶段优化第二次尝试的准确性,同时约束第一次尝试保持基础模型分布,以防止行为坍缩;第二阶段则采用强化学习,并结合奖励塑形机制,引导模型逐步修正错误,而非简单复制初始答案。实验结果表明,SCoRe 在数学推理(MATH)和代码生成(HumanEval、MBPP)任务中均取得了显著提升,优于现有方法。此外,SCoRe 还能与自一致性解码结合,提高推理计算效率。尽管方法仍有改进空间,如扩展至更多轮自我纠正或优化训练成本,但研究结果表明,SCoRe 为 LLM 的自我纠正训练提供了一条有效的强化学习路径,并在科学推理任务中展现出广泛的应用潜力。

